Background
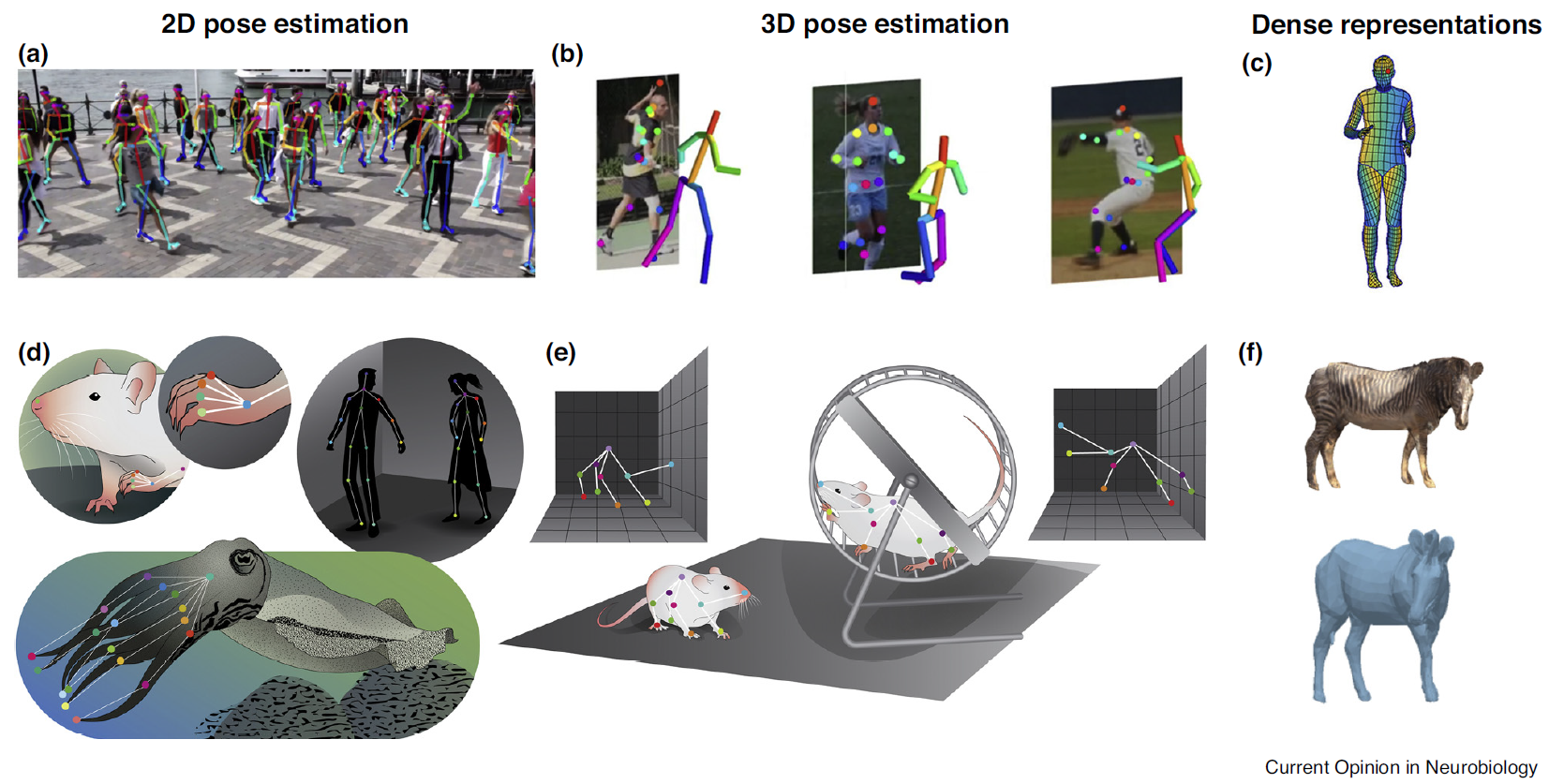
Understanding the behavior of primates is important for primatology, psychology, and for biology more broadly since primates are an important model organism, and whose behavior is often an important variable of interest. However, our ability to rigorously quantify behavior has long been limited, due to the high manual cost of observing and the difficulty in long-term observing in the wild. Behavioral tracking in primates has recently become possible through parallel developments in computer vision, machine learning, and robotics when technical breakthroughs in deep learning enabled software to recognize objects in an image by use of CNN. Several works enable automatic tracking of humans (Cao et al., 2019 Newell et al., 2016). These works in turn inspired and facilitated work that allowed for the tracking of animals such as flies, mice, and horses from videos (Mathis et al., 2018; Pereira et al., 2019).
We cooperate with Prof. Federico, an associate professor in the Cognitive Science department at UC San Diego and the director of the Comparative Cognition Laboratory. He has collected the largest video longitudinal dataset of baby apes (4000 hours of videos from 31 animals). The data we’re going to use in this project is some sample videos collected in Leipzig zoo. The objects in the videos are a group of chimpanzees living in Leipzig zoo, and each of the chimpanzees has its own name and other information such as gender, birth date, blood relationship, etc. Focal shooting, a common and effective practice in studying primates, is usually used, where an observer records one animal for a set length of time and writes down everything that animal does, with times noted. For example, the following video clip is focusing on the infant chimpanzee, Azibo, who is carried by his mother, Swela. Cognitive scientists have to manually check and code all the footage to obtain statistical conclusions so as to understand the behavior of these primates, which is a heavy and error-prone process. And it is almost impossible to observe an individual longitudinally across its life span.

The automatic ability to track and analyze the behaviors of primates will largely help the cognitive science community to promote research progress. To that end, given a video clip containing in-the-wild chimpanzees which are partially annotated, we need to first percept all of them – where they are (detection), who they are (identification), and what they are doing (2D pose estimation), then, we could quantitatively draw a social network and deduce the social relations among them. (Bain et al., 2021)
Data
We provide two types of annotation, with corresponding images, and source videos, for three hierarchical problems. Download the data and the data directory should be
|-- data
|-- images
| |-- ck7cirx61co8n0866o238jftr.jpg
| |-- ck7cjd9nz967908077avy721p.jpg
| `-- ...
|-- labels_detect
| |-- train
| |-- |-- ck7cirx61co8n0866o238jftr.txt
| `-- -- ...
| |-- val
| |-- |-- ck7e79q7z1t310807xayi3ew8.txt
| `-- -- ...
|-- labels_id
| |-- train
| |-- |-- ck7ntu3hcasba075238bi3v5j.txt
| `-- -- ...
| |-- val
| |-- |-- ck7ntw7h7efw20866iahi95kt.txt
| `-- -- ...
|-- videos
|-- check_label_detect.py
`-- check_label_id.py
Data format
- images
- 1351 images
- labels_detect (Detection)
- For each image named
xxxx.jpg, there is a corresponding annotation file namedxxxx.txtin this folder. - Note that we’ve already split
trainandvalsubset annotations in the corresponding folder. - 4615 detection annotations for train, and 346 detection annotations for validation.
- Each line describes an object, and the location of the bounding box, where
cls_idis all 0, which means they are all the same class (chimpanzee). Note that the location of the bounding box is the ratio of the bounding box size with regard to the original image size. More details could be found in the visualization scripts.
cls_id, centerx, centery, bboxw, bboxh - For each image named
- labels_id (Identification)
- For each image named
xxxx.jpg, there is a corresponding annotation file namedxxxx.txtin this folder. - Note that we’ve already split
trainandvalsubset annotations in the corresponding folder. - 662 id annotations for train, and 275 id annotations for validation.
- Each line describes an object, and the location of the bounding box, where
name_idis the name id, which denotes its identity. Note that the location of the bounding box is the ratio of the bounding box size with regard to the original image size. More details could be found in the visualization scripts.
name_id, centerx, centery, bboxw, bboxh - For each image named
- videos
- 5 videos, which are the source videos of the
images - Could be used to make a demo if needed.
- 5 videos, which are the source videos of the
check_label_detect.py- A script to visualize the detection annotations, the results will be saved in a new folder named
vis_labels_detect(created when running).
python check_label_detect.py- A script to visualize the detection annotations, the results will be saved in a new folder named
check_label_id.py- A script to visualize the id annotations, the results will be saved in a new folder named
vis_labels_id(created when running).
python check_label_id.py- A script to visualize the id annotations, the results will be saved in a new folder named
- Online information
- Age & gender: Leipzig zoo website
Note
Please note that the labels under labels_detect and labels_id are not absolutely clean, i.e., there will be some label files that are null. Your code should handle these invalid label files.
Here is what the data looks like after running the visualization scripts.
Basic Problem (50 points): Detection
TODO
Detect all the chimpanzees in each frame. You could use open-source repositories such as YOLO series. You are encouraged to only use the train subset for training, and evaluate the model performance on the validation subset. Commonly-used metrics such as AP should be reported.
Submit
- Working code (github)
- Pre-trained model checkpoints
- Write down in any form:
- what problems have you encountered along the way
- what improvements have you made to the algorithm
- what attempts you made along the way to achieve the final goal
Evaluation
- Code (70%):
- Clear structure with a readable README file. (10%)
- Clean the data and reproduce existing baselines with it. (40%)
- Modify the model, and improve performance to a certain extent compared with the baseline. (20%)
- The recorded file (30%)
- Analyze problems coherently. (10%)
- Propose targeted solutions and explain the reason. (10%)
- Make a video demo using the provided videos, where the detection results are shown in the video. (10%)
Bonus Problem - Identification (30 points)
TODO
Identify each individual in each frame. Based on the detection results, you could design an identification head network to classify each object. You are encouraged to only use the train subset for training, and evaluate the model performance on the validation subset. Commonly-used metrics such as top-1 or top-5 accuracy should be reported.
Tips: The annotation distribution is a long-tailed distribution like below. And the labels are very limited. Therefore, only supervised learning may not be enough. Some novel techniques such as contrastive learning could be considered. Feel free to google it!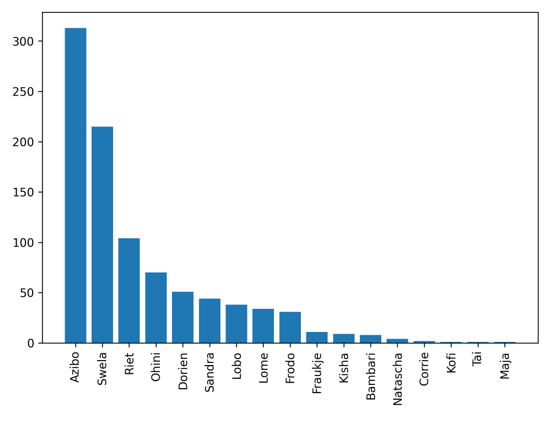
Submit
- Working code (github)
- Pre-trained model checkpoints
- Write down in any form:
- what problems have you encountered along the way
- what improvements have you made to the algorithm
- what attempts you made along the way to achieve the final goal
Evaluation
- Code (70%):
- Clear structure with a readable README file. (10%)
- Clean the data and reproduce existing baselines with it. (40%)
- Modify the model, and improve performance to a certain extent compared with the baseline. (20%)
- The recorded file (30%)
- Analyze problems coherently. (10%)
- Propose targeted solutions and explain the reason. (10%)
- Make a video demo using the provided videos, where the detection and identification results are shown together in the video. (10%)
Bonus/Open Problem - 2D pose estimation (20 points)
TODO
Since the 2D pose annotations for primates are hard to obtain. Few-shot or transfer learning with an existing 2D human pose estimator such as Alpha Pose could make primate pose estimation become possible. In addition, MacaquePose is an existing 2D pose annotation for primates. You could also utilize them to help with the 2D pose estimation for the Leipzig chimpanzee.
Tips: Multi-object 2D pose estimation can be divided into two classes, top-down or bottom-up. You are encouraged to choose either of them to build the model. More details could be found in (Cao et al. 2019), Alpha Pose. Feel free to google it!
Submit
- Working code (github)
- Pre-trained model checkpoints
- Write down in any form:
- what problems have you encountered along the way
- what improvements have you made to the algorithm
- what attempts you made along the way to achieve the final goal
Evaluation
- Code (70%):
- Clear structure with a readable README file. (10%)
- Search available data, clean the data, and use existing 2D pose datasets such as MacaquePose to train a primate 2D pose estimation baseline. (40%)
- Modify the model, and improve performance to a certain extent compared with the baseline. (20%)
- The recorded file (30%)
- Analyze problems coherently. (10%)
- Propose targeted solutions and explain the reason. (10%)
- Make a video demo using the provided videos, where the detection, identification, and 2D pose estimation results are shown together in the video. (10%)
Reference Demo Results (on GDrive)
- The video below shows the bounding box detection and tracking result.
ID, confidenceis shown above each bounding box, which denotes the tracking identity across frames.
- The video below shows the bounding box detection result with its ID name on it.
- The video below shows the bounding box detection result, 2D pose estimation, age class, and gender estimation results on in-the-wild unseen videos.
As you can see in the demo, there are many artifacts in the estimated results, which may be improved with more interpretability techniques to help (reasoning about the occlusion, tracking helps identification, etc). Let’s brainstorm!
Reference
Cao, Z., Hidalgo, G., Simon, T., Wei, S. E., & Sheikh, Y. (2019). OpenPose: realtime multiperson 2D pose estimation using Part Affinity Fields. IEEE transactions on pattern analysis and machine intelligence, 43(1), 172-186.
Newell, A., Yang, K., & Deng, J. (2016). Stacked hourglass networks for human pose estimation. In European conference on computer vision (pp. 483-499).
Mathis, A., Mamidanna, P., Cury, K. M., Abe, T., Murthy, V. N., Mathis, M. W., & Bethge, M. (2018). DeepLabCut: markerless pose estimation of user-defined body parts with deep learning. Nature neuroscience, 21(9), 1281-1289.
Pereira, T. D., Aldarondo, D. E., Willmore, L., Kislin, M., Wang, S. S. H., Murthy, M., & Shaevitz, J. W. (2019). Fast animal pose estimation using deep neural networks. Nature methods, 16(1), 117-125.
Bain, M., Nagrani, A., Schofield, D., Berdugo, S., Bessa, J., Owen, J., … & Zisserman, A. (2021). Automated audiovisual behavior recognition in wild primates. Science advances, 7(46), eabi4883.
Labuguen, R., Matsumoto, J., Negrete, S. B., Nishimaru, H., Nishijo, H., Takada, M., … & Shibata, T. (2021). MacaquePose: A novel “in the wild” macaque monkey pose dataset for markerless motion capture. Frontiers in behavioral neuroscience, 14, 581154.