[ECCV18] Holistic 3D Scene Parsing and Reconstruction from a Single RGB Image
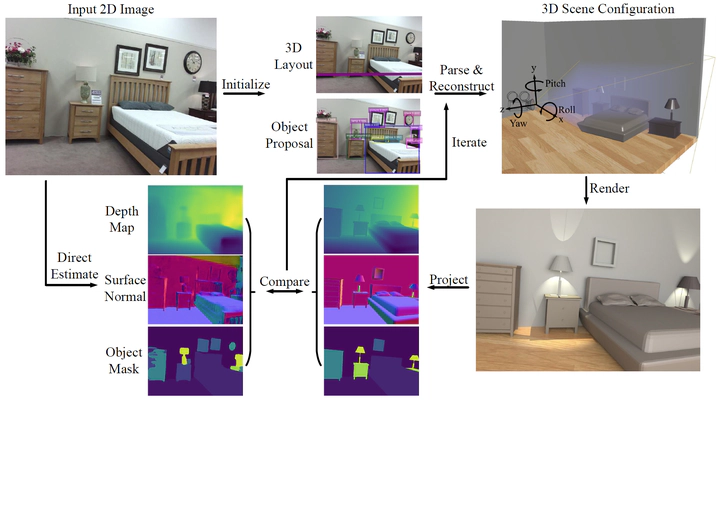 Illustration of the proposed holistic 3D indoor scene parsing and reconstruction in an analysis-by synthesis fashion. A 3D representation is initialized by individual vision modules (e.g., object detection, 2D layout estimation). A joint inference algorithm compares the differences between the rendered normal, depth, and segmentation map with the ones estimated directly from the input RGB image, and adjust the 3D structure iteratively.
Illustration of the proposed holistic 3D indoor scene parsing and reconstruction in an analysis-by synthesis fashion. A 3D representation is initialized by individual vision modules (e.g., object detection, 2D layout estimation). A joint inference algorithm compares the differences between the rendered normal, depth, and segmentation map with the ones estimated directly from the input RGB image, and adjust the 3D structure iteratively.Abstract
We propose a computational framework to jointly parse a single RGB image and reconstruct a holistic 3D configuration composed by a set of CAD models using a stochastic grammar model. Specifically, we introduce a Holistic Scene Grammar (HSG) to represent the 3D scene structure, which characterizes a joint distribution over the functional and geometric space of indoor scenes. The proposed Holistic Scene Grammar (HSG) captures three essential and often latent dimensions of the indoor scenes: i) latent human context, describing the affordance and the functionality of a room arrangement, ii) geometric constraints over the scene configurations, and iii) physical constraints that guarantee physically plausible parsing and reconstruction. We solve this joint parsing and reconstruction problem in an analysis-by-synthesis fashion, seeking to minimize the differences between the input image and the rendered images generated by our 3D representation, over the space of depth, surface normal, and object segmentation map. The optimal configuration, represented by a parse graph, is inferred using Markov chain Monte Carlo (MCMC), which efficiently traverses through the non-differentiable solution space, jointly optimizing object localization, 3D layout, and hidden human context. Experimental results demonstrate that the proposed algorithm improves the generalization ability and significantly outperforms prior methods on 3D layout estimation, 3D object detection, and holistic scene understanding.