[CVPR21] Learning Triadic Belief Dynamics in Nonverbal Communication from Videos
Abstract
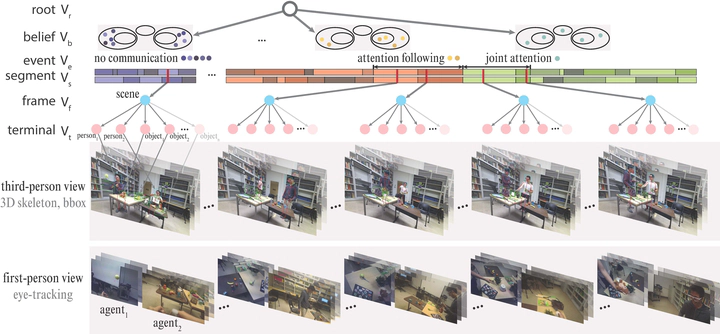
Humans possess a unique social cognition capability; nonverbal communication can convey rich social information among agents. In contrast, such crucial social characteristics are mostly missing in the existing sceneunderstanding literature. In this paper, we incorporate different nonverbal communication cues (e.g., gaze, humanposes, and gestures) to represent, model, learn, and infer agents’ mental states from pure visual inputs. Crucially, such a mental representation takes the agent’s belief into account so that it represents what the true world state is and infers the beliefs in each agent’s mental state, which may differ from the true world states. By aggregating different beliefs and true world states, our model essentially forms “five minds” during the interactions between two agents. This “five minds” model differs from prior works that infer beliefs in an infinite recursion; instead, agents’ beliefs are converged into a “common mind”. Based on this representation, we further devise a hierarchical energy-based model that jointly tracks and predicts all five minds. From this new perspective, a social event is interpreted by a series of nonverbal communication and belief dynamics, which transcends the classic keyframe video summary. In the experiments, we demonstrate that using such a social account provides a better video summary on videos with rich social interactions compared with state-of-the-artkeyframe video summary methods.