[ICLR24] SparseDFF: Sparse-View Feature Distillation for One-Shot Dexterous Manipulation
Abstract
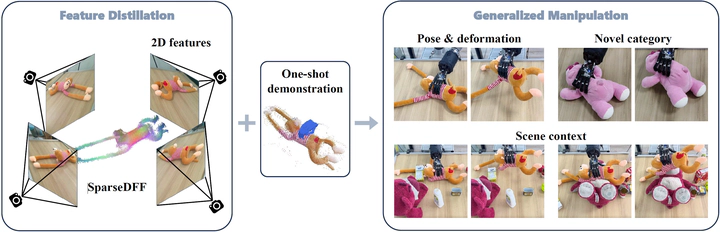
Humans demonstrate remarkable skill in transferring manipulation abilities across objects of varying shapes, poses, and appearances, a capability rooted in their understanding of semantic correspondences between different instances. To equip robots with a similar high-level comprehension, we present SparseDFF, a novel DFF for 3D scenes utilizing large 2D vision models to extract semantic features from sparse RGBD images, a domain where research is limited despite its relevance to many tasks with fixed-camera setups. SparseDFF generates view-consistent 3D DFFs, enabling efficient one-shot learning of dexterous manipulations by mapping image features to a 3D point cloud. Central to SparseDFF is a feature refinement network, optimized with a contrastive loss between views and a point-pruning mechanism for feature continuity. This facilitates the minimization of feature discrepancies w.r.t. end-effector parameters, bridging demonstrations and target manipulations. Validated in real-world scenarios with a dexterous hand, SparseDFF proves effective in manipulating both rigid and deformable objects, demonstrating significant generalization capabilities across object and scene variations