Abstract
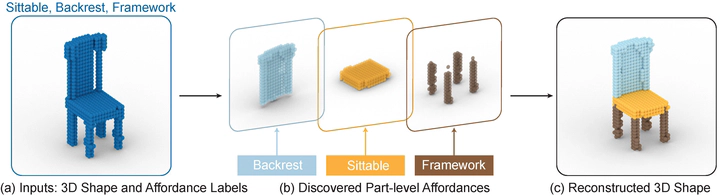
Understanding what objects could furnish for humans-namely, learning object affordance-is the crux to bridge perception and action. In the vision community, prior work primarily focuses on learning object affordance with dense (e.g., at a per-pixel level) supervision. In stark contrast, we humans learn the object affordance without dense labels. As such, the fundamental question to devise a computational model is: What is the natural way to learn the object affordance from visual appearance and geometry with humanlike sparse supervision? In this work, we present a new task of part-level affordance discovery (PartAfford): Given only the affordance labels per object, the machine is tasked to (i) decompose 3D shapes into parts and (ii) discover how each part of the object corresponds to a certain affordance category. We propose a novel learning framework for PartAfford, which discovers part-level representations by leveraging only the affordance set supervision and geometric primitive regularization, without dense supervision. The proposed approach consists of two main components: (i) an abstraction encoder with slot attention for unsupervised clustering and abstraction, and (ii) an affordance decoder with branches for part reconstruction, affordance prediction, and cuboidal primitive regularization. To learn and evaluate PartAfford, we construct a part-level, cross-category 3D object affordance dataset, annotated with 24 affordance categories shared among >25, 000 objects. We demonstrate that our method enables both the abstraction of 3D objects and part-level affordance discovery, with generalizability to difficult and cross-category examples. Further ablations reveal the contribution of each component.