Abstract
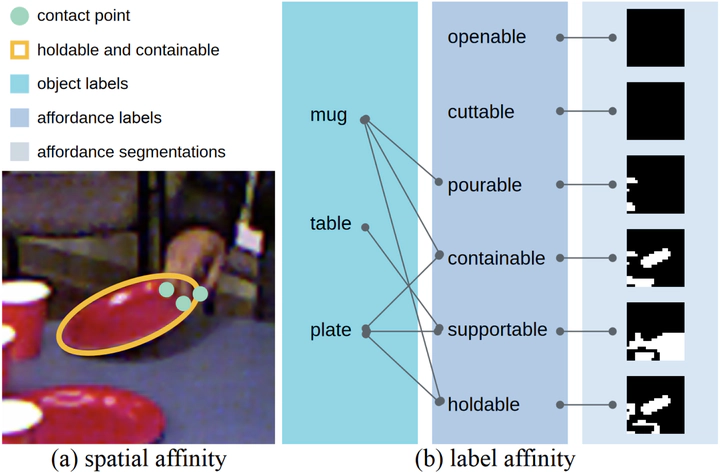
With significant annotation savings, point supervision has been proven effective for numerous 2D and 3D scene understanding problems. This success is primarily attributed to the structured output space; i.e., samples with high spatial affinity tend to share the same labels. Sharing this spirit, we study affordance segmentation with point supervision, wherein the setting inherits an unexplored dual affinity—spatial affinity and label affinity. By label affinity, we refer to affordance segmentation as a multi-label prediction problem: A plate can be both holdable and containable. By spatial affinity, we refer to a universal prior that nearby pixels with similar visual features should share the same point annotation. To tackle label affinity, we devise a dense prediction network that enhances label relations by effectively densifying labels in a new domain (i.e., label co-occurrence). To address spatial affinity, we exploit a Transformer backbone for global patch interaction and a regularization loss. In experiments, we benchmark our method on the challenging CAD120 dataset, showing significant performance gains over prior methods.