项目背景与目标
人类如何从高维感官输入中提取有意义的特征,并形成层次化的概念体系,是认知科学和人工智能领域的核心问题之一。传统概念学习研究受限于现实物体的特征不可控性和组合有限性,难以系统探索特征空间结构与概念形成动态机制间的关系。而在行为心理学研究中,使用计算机生成的刺激物有着悠久的历史 (Kasarda et al., 2025)。一般认为Shepard和Metzler最早利用由计算机生成并伴有图形输出的新型3D物体来研究对物理动作的心理模拟 (Shepard et al., 1971)。此后,视觉刺激物的艺术创作一直受到计算机图形技术进步的推动。Cutzu和Edelman通过在70维空间生成的3D刺激证明人类视觉系统能够支持三维物体之间相似性的度量准确表示(Cutzu and Edelman, 1998)。还有两个经典例子是Greebles (Gauthier et al., 1997)和Fribbles (Williams, 1997)数据集,这两者已被用于数百项心理物理学、认知科学、认知神经科学和临床研究中。
本项目旨在构建一个基于生成式AI技术的3D合成物体生成系统,通过精确控制视觉特征维度及其组合规则,研究人类表征学习与概念形成的动态认知推理和神经计算机制,为探索类人和类脑学习提供全新的实验刺激平台。通过该平台,可以生成一套现实中不存在的3D合成物体,这些物体具有可分解的视觉特征维度(如形状、纹理、颜色、结构等),支持特征的自由组合与类别结构的构建,为概念学习实验提供高度可控的刺激材料。在这些合成物体的基础上,我们将深入探索人类在视觉-语义交互过程中的特征学习、概念形成及结构知识表征的动态计算机制。
系统核心目标是:
- 支持生成至少10,000个高复杂度3D物体样本,覆盖多种特征维度(如上面提到的形状、纹理等)和组合方式,并能够从多角度渲染呈现。利用公开数据集或自动生成标准化数据集,实现合成物体数据自动化生成与批量处理脚本。
- 设计结构化物体概念生成器和检索算法,实现不同结构类别的生成和跨类别、跨结构信息整合。
- 在物体生成、特征组合、概念结构等环节引入多层次复杂度评估与性能测试,参考LongMemEval(Wu et al., 2024)/ LOCOMO(Maharana et al., 2024)等基准设计评测流程。
- 实现完整的流水线,从特征空间和组合空间的所有控制参数到最终生成的物体模型文件和不同条件的渲染图像,包括高效的3D建模、多角度渲染、数据导出、复杂检索等功能。
核心任务设计
任务一:特征生成与组合系统(40分)
设计并实现一个参数化3D物体生成系统,支持多种视觉特征维度的独立控制与组合生成。系统包括至少3个关键模块:形状生成器(支持几何基元、复杂多边形及自定义形状的生成与组合);表面纹理与颜色引擎(生成多样化皮肤纹理、颜色模式及光学属性);结构组装系统(支持部件组合、对称性控制、空间关系调整)。给定各模块特征维度的参数,系统应能生成对应特征组合的3D物体。

需对每个关键模块设计并建立量化评估体系,建议包括特征参数、特征独立性指标、刺激复杂度指标等,简要介绍各量化指标的计算方式,便于后续认知实验的自变量设计及学习过程的量化分析。
- 可以使用“部件库 + 组合规则”方式构建对象。先定义基元部件(如方块、球、杆等)和连接规则(连接点、对称、层级),通过随机/受控采样生成实例。部件库可以采用已有的数据集如ShapeNet(Chang et al., 2015)、ModelNet(Wu et al., 2015)、PartNet(Mo et al., 2019)等,也可以自己生成,例如在已有数据集的基础上训练生成模型(diffusion model等)。
- 设计多种组合规则(如层级组合、随机组合、受控组合),并对组合复杂度进行量化分析。可以使用Blender Geometry Nodes或PythonSCAD(Python + OpenSCAD)实现参数化建模与部件组合。
- 支持自动化批量生成和导出,单次生成不少于1,000个样本。
- 对生成物体的特征分布、类别覆盖度、刺激复杂度等进行统计分析。
任务二:3D物体建模与渲染系统(20分)
开发3D物体实时渲染系统,实现从特征参数到高质量3D模型的输出,支持多角度、任意视角、光照条件的渲染控制,并支持批量导出不同角度、大小、光照条件下的2D渲染图像,以及3D模型文件(如.obj),便于实验刺激呈现和实时交互学习任务的设计。
推荐Blender或Unity engine 用于3D物体生成。
- 实现自动化渲染脚本,支持批量渲染和导出。推荐 BlenderProc(基于 Blender 的可编程数据流水线)或 Kubric(Google开发可扩展合成器)(Greff et al., 2022)来做大规模、分布式渲染任务。
- 渲染结果需覆盖不少于10种视角和5种光照条件。实现至少10个固定相机与1个随机相机策略(俯仰/方位/距离/焦距),并实现5种光照策略(点光 + 环境 HDRI + 方向光 + 多光源随机化 + 柔光/硬光切换)。
- 对渲染质量、速度和资源消耗进行性能测试和统计。Blender 支持 Cycles(光线追踪)与 Eevee(实时)渲染,二者可按速度/质量取舍。如使用其他工具也请自行衡量与统计。
任务三:复杂概念结构生成与检索算法(40分)
设计支持个体、变体、基类等结构化种属、关系生成器,根据视觉特征及组合规则生成不同结构类别。概念结构需支持层级结构、树状结构、网络结构等多种类型,并可以涵盖连续特征空间中所有的特征组合。在此基础上,实现检索算法,用于根据指定条件筛选概念结构中符合要求的物体样本。最后,设计算法量化结构复杂度和检索准确率等指标。
下图展示了一个最简单局部层级结构的示例。
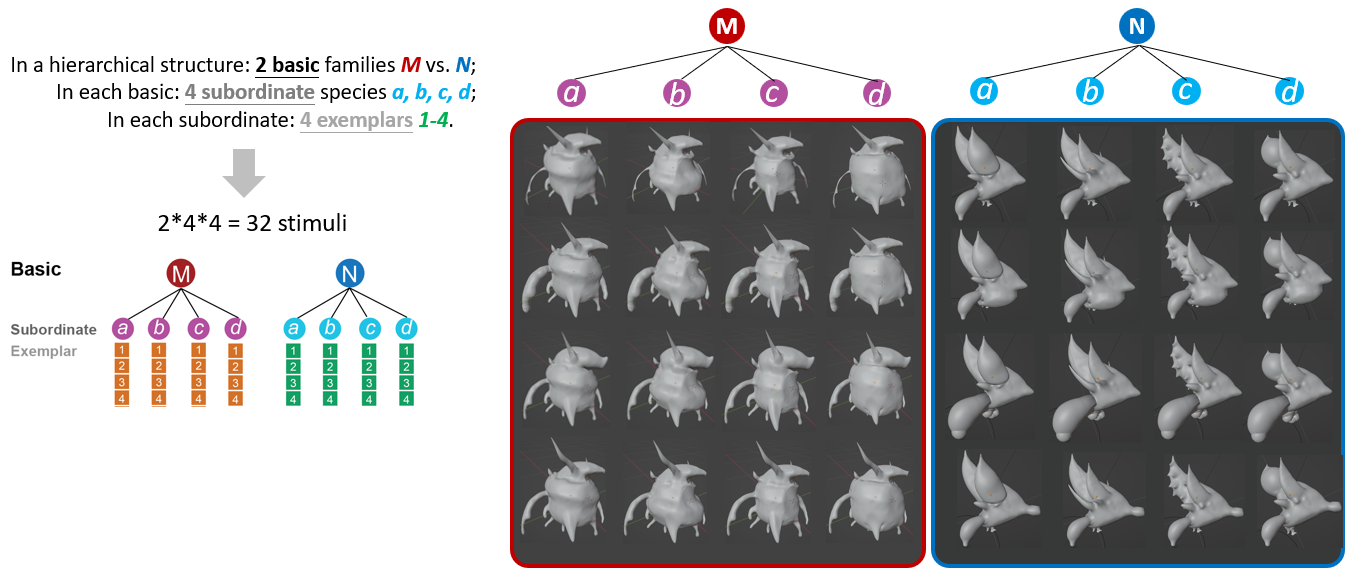
可行方案及要求:
- 可以仿照语法树/图的方法,把“概念结构”表示为部件-关系图,通过生成图(grammar graph)产生层次化概念(基类→变体→个体);也可以从参数化特征空间中抽取特征向量(例如形状编码+纹理编码+组合结构编码等),再用聚类/层次聚类构造“类-亚类”分层。
- 实现复杂检索算法(如多条件检索、模糊检索、时序检索),支持跨类别、跨层级信息整合。对于多条件检索,可以使用属性过滤+向量检索(如FAISS (Douze et al., 2024) / Annoy)的方法,先把所有样本的语义/视觉信息编码成向量,查询时先做条件属性过滤,再对剩余候选对象做向量相似度排序;对于模糊检索,可以采用语义编码(Sentence-BERT, CLIP等)+向量检索的方法;对于时序检索,可以采用序列模式匹配算法,把一组物体特征按时间或属性排序,用序列对齐算法(Dynamic Time Warping, DTW)计算距离。
- 对结构复杂度、检索准确率、样本覆盖度等进行量化评估。
- 在检索算法的基础上,设计样本采样策略,支持大规模实验和自动化测试。
任务四:语义编码与视觉-语言交互接口(附加题)
物体合成系统搭建完成后,可以构建支持自然语言描述的物体特征编码系统。(示例编码:物理语义特征:“光滑表面”、“多棱角结构”等;抽象语义特征:“类生物体”、“机械结构”、“奇幻物体”等。)基于语义特征编码,设计描述生成器,为每个生物体自动生成特征描述文本;开发交互式标注界面,支持用户对物体进行语义标注和验证。该系统可支持底层视觉特征(Gabor features)到语义特征(semantic embedding)的双向对齐,用于探索概念学习过程中知觉信息-语义信息-抽象概念形成的动态发展过程。
- 实现每个物体的特征语义编码,并自动生成语义描述文本。先用模板化描述把参数向量(颜色、材质、形状等)转成“可控句子”,再用BLIP-2(Li et al., 2023)或其他caption模型对渲染图做描述增强/润色。确保语义编码能够支持多层次(具象-抽象)和多语言(如中英文)描述。
- 开发支持批量标注和验证的界面,可以利用Label Studio / CVAT等工具平台开发,前端若需3D交互可用react-three-fiber(Three.js)做3D模型浏览/旋转/部件打标。
- 实现语义检索和语义相似度分析,支持复杂语义查询。可以用CLIP把渲染图像和文本嵌入到同一空间,作为“零样本检索”和相似度评估基础,用 Sentence-Transformers做文本重排与多语言语义搜索。
- 设计知识动态更新机制,支持语义标签的自动修正和演化。可以对语义分类器/编码做增量微调,也可以用向量聚类+检测冲突标签并召回的方法修正相似样本标签。
数据集与技术栈
核心数据集:
- 部件数据库:ShapeNet, ModelNet, PartNet等(可选)
- 工具库:Oomplet Dataset Toolkit(可选)
推荐技术栈:
- 参数化几何建模:OpenSCAD / Blender Geometry Nodes / Houdini Geometry Nodes
- 3D渲染:Blender / Unity engine / Kubric
- 概念结构生成:Grammar graph, GNN
- 检索算法:FAISS, Annoy, DTW
- 多模态语义编码:CLIP, BLIP-2
- 标注平台:Label Studio / CVAT
- 深度学习:PyTorch / TensorFlow
评估标准与预期成果
评分分配(100分):
- 特征及规则生成(40分)重点考察特征维度丰富性、新颖性,组合灵活性以及特征评估指标的完整性。
- 3D渲染(20分)评估模型质量、渲染效果以及实时交互渲染能力。
- 复杂概念结构与检索(40分)关注结构种类的复杂度多样性、检索算法的效率和准确性。
- 语义编码(附加题)考察具象-抽象语义特点的层次划分、语义检索与知识更新能力。
预期交付物:
- 完整系统代码(GitHub仓库),包含10,000+样本的标准化数据集,并提供不少于5种不同概念分类标准示例
- 自动化测试脚本和部署说明
- 详细技术报告(含系统架构、算法原理、评估指标和评估结果)
参考文献
- Kasarda, J. P., Zhang, A., Tong, H., Tan, Y., Wang, R., Verstynen, T., & Tarr, M. J. (2025). The Oomplet dataset toolkit as a flexible and extensible system for large-scale, multi-category image generation. Scientific Reports, 15(1), 9287.
- Cutzu, F., & Edelman, S. (1998). Representation of object similarity in human vision: psychophysics and a computational model. Vision research, 38(15-16), 2229-2257.
- Shepard, R. N., & Metzler, J. (1971). Mental rotation of three-dimensional objects. Science, 171(3972), 701-703.
- Gauthier, I., & Tarr, M. J. (1997). Becoming a “Greeble” expert: Exploring mechanisms for face recognition. Vision research, 37(12), 1673-1682.
- Williams, P. (1997). Prototypes, exemplars, and object recognition. Yale University.
- Chang, A. X., Funkhouser, T., Guibas, L., Hanrahan, P., Huang, Q., Li, Z., … & Yu, F. (2015). Shapenet: An information-rich 3d model repository. arXiv preprint arXiv:1512.03012.
- Wu, Z., Song, S., Khosla, A., Yu, F., Zhang, L., Tang, X., & Xiao, J. (2015). 3d shapenets: A deep representation for volumetric shapes. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 1912-1920).
- Mo, K., Zhu, S., Chang, A. X., Yi, L., Tripathi, S., Guibas, L. J., & Su, H. (2019). Partnet: A large-scale benchmark for fine-grained and hierarchical part-level 3d object understanding. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 909-918).
- Wu, D., Wang, H., Yu, W., Zhang, Y., Chang, K. W., & Yu, D. (2024). Longmemeval: Benchmarking chat assistants on long-term interactive memory. arXiv preprint arXiv:2410.10813.
- Maharana, A., Lee, D. H., Tulyakov, S., Bansal, M., Barbieri, F., & Fang, Y. (2024). Evaluating very long-term conversational memory of llm agents. arXiv preprint arXiv:2402.17753.
- Greff, K., Belletti, F., Beyer, L., Doersch, C., Du, Y., Duckworth, D., … & Tagliasacchi, A. (2022). Kubric: A scalable dataset generator. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 3749-3761).
- Douze, M., Guzhva, A., Deng, C., Johnson, J., Szilvasy, G., Mazaré, P. E., … & Jégou, H. (2024). The faiss library. arXiv preprint arXiv:2401.08281.
- Li, J., Li, D., Savarese, S., & Hoi, S. (2023, July). Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. In International conference on machine learning (pp. 19730-19742). PMLR.